Mono & Flux
0. 前言
最近后端项目上大量用到了WebFlux的技术,代码中充斥着大量Mono.just和Flux.just的身影,令我困惑的是,Mono是啥意思,Flux又是什么,为什么要just,所以利用了周日的时间快速地对这块领域进行补齐~ 奥,对了,这篇笔记会采用我从0-1的思维顺序来做记录(算是一种跟往常不一样的叙述方式吧
1. 什么是WebFlux?
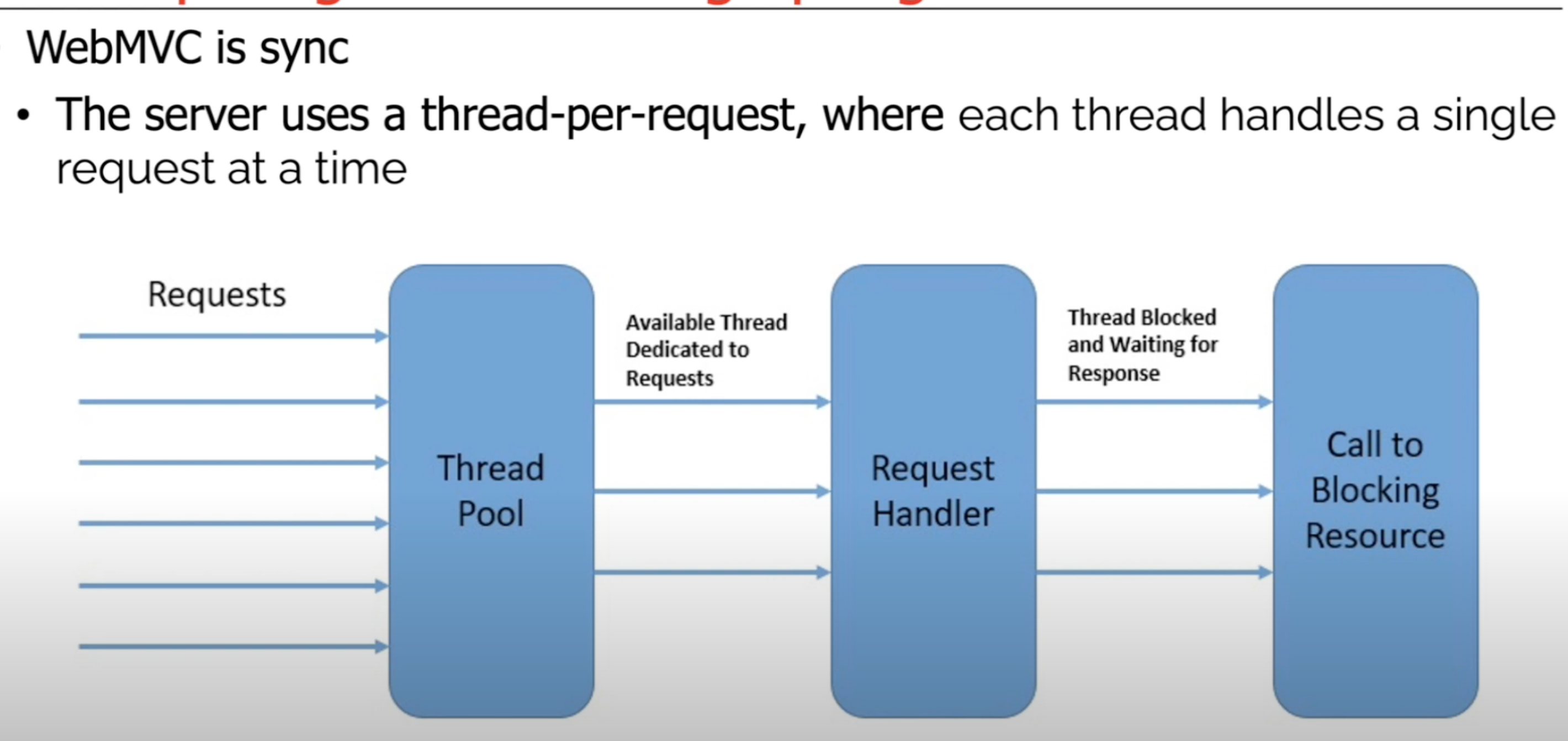
根据传统的Spring MVC框架,我们可以知道一个HTTP请求,从开始到结束之间的代码都是顺序同步执行的,也就是说,对应该请求背后的每一个动作都是串行化的,也称之为命令式编程,在命令式编程中,代码按照编写的顺序一步步执行,每一步都会等待前一步完成后才继续执行,这种方式的缺点就是当一个请求中的多个步骤,存在某个耗时步骤时,可能会由于该步骤阻塞而影响了后续步骤的执行
那么Spring WebFlux的表现形式则与以上大有不同,它是一个异步非阻塞式的 Web 框架,它能够充分利用多核 CPU 的硬件资源去处理大量的并发请求,也就是说,同样一个请求,其中包含同样的流程步骤,所有的步骤都可以进行自定义异步处理,并且能够达到并行解决各个步骤的效果,基于此能够减少由于阻塞导致的低性能,称之为响应式编程
- 命令式编程

- 响应式编程
WebFlux 内部使用的是响应式编程「Reactive Programming」,以 Reactor 库为基础,基于异步和事件驱动,可以在不扩充硬件资源的前提下,提升系统的吞吐量和伸缩性
2. 命令式编程 & 响应式编程
命令式编程:
- 控制流程: 命令式编程是我们通常所熟悉的编程范式,它通过明确的控制流程语句(例如循环、条件语句)来实现程序逻辑
- 同步执行: 在命令式编程中,代码按照编写的顺序一步步执行,每一步都会等待前一步完成后才继续执行,这可能导致阻塞,特别是在需要等待长时间操作完成的情况下
- 阻塞模式: 命令式编程在处理多个任务时,往往会使用阻塞模式,即一个任务的执行会阻塞其他任务的执行,直到当前任务完成
响应式编程:
- 事件驱动: 响应式编程强调使用事件和数据流来驱动程序逻辑。程序会对事件做出响应,而不是通过显式的控制流程来驱动
- 异步非阻塞: 在响应式编程中,任务的执行不会阻塞主线程或其他任务的执行。异步操作允许在任务等待的时候继续执行其他任务,从而提高系统的并发性和性能
- 流式处理: 响应式编程强调使用流式处理来处理数据。数据流可以由多个事件组成,程序会响应这些事件并执行相应的操作
在 Spring 框架的不同模块中,有以下两种不同的组合:
- Spring MVC + Servlet + Tomcat: 这是基于传统的命令式编程模型,在传统的 Servlet 编程中,使用 Servlet 规范和 Tomcat 服务器,代码按照编写的顺序同步执行,可能会导致阻塞,特别是在处理大量并发请求时
- Spring WebFlux + Reactor + Netty: 这是一种响应式编程模型,在 Spring WebFlux 中,使用 Reactor 框架和 Netty 服务器,代码采用异步非阻塞方式运行,允许处理大量并发请求而不会阻塞线程,从而提高系统的并发性和性能
响应式编程适用于需要高并发和高吞吐量的场景,尤其在处理异步操作和事件驱动任务时非常有用
命令式编程则更适用于相对简单的同步操作,但在处理大量并发请求时可能会面临性能瓶颈
3. 为什么要叫Reactive?
以下源于Spring WebFlux官网解释
We touched on “non-blocking” and “functional” but what does reactive mean?
The term, “reactive,” refers to programming models that are built around reacting to change — network components reacting to I/O events, UI controllers reacting to mouse events, and others. In that sense, non-blocking is reactive, because, instead of being blocked, we are now in the mode of reacting to notifications as operations complete or data becomes available.
There is also another important mechanism that we on the Spring team associate with “reactive” and that is non-blocking back pressure. In synchronous, imperative code, blocking calls serve as a natural form of back pressure that forces the caller to wait. In non-blocking code, it becomes important to control the rate of events so that a fast producer does not overwhelm its destination.
Reactive Streams is a small spec (also adopted in Java 9) that defines the interaction between asynchronous components with back pressure. For example a data repository (acting as Publisher) can produce data that an HTTP server (acting as Subscriber) can then write to the response. The main purpose of Reactive Streams is to let the subscriber control how quickly or how slowly the publisher produces data.
总的来讲,Reactive这个术语指的是对变化做出响应而构建的编程模型,核心思想是指通过对变化做出即时反应来实现系统的交互和处理,而其中非阻塞和函数式则是这个编程模型的两个重要的特点,在响应式模型中,我们不再被阻塞,而是处于对操作完成或数据可用时的通知做出反应的状态
4. 什么是背压 (Backpressure)?
响应式模型还有一个概念叫 非阻塞背压 (non-blocking back pressure),在以往的命令式模型中,阻塞调用可以作为一种自然的背压形式,强调调用者等待
我们可以想象代码中存在一个方法,调用方法端和执行方法端形成了2种角色:生产者 & 消费者,其中生产者指代的是执行方法端,而消费者指代的是调用方法端,如果考虑一个生产者和一个消费者之间的数据流传输,例如一个生产者生成大量的数据,而消费者可能处理这些数据的速度相对较慢,如果没有适当的背压机制,生产者可能会迅速生成大量数据,导致消费者难以处理,从而可能引发内存溢出或性能下降,因此,在响应式编程中,Reactive Streams 规范引入了一种标准化的背压机制,允许数据的生产者和消费者之间通过背压信号进行通信,以调整数据流的速率,从而确保系统的稳定性和性能,这种机制允许消费者控制生产者的速率,以适应不同处理速度的场景

简单的理解,背压这个词要依据具体情况来看:
- 背压现象:指的是 生产速率过快 而消费端跟不上
- 背压机制:指的是一种预防背压现象出现的机制
5. 使用Spring WebFlux需要引入哪个依赖?
- Gradle方式
1 | implementation 'org.springframework.boot:spring-boot-starter-webflux' |
- Maven方式
1 | <dependency> |
在引入完以上代码后,需要确保依赖中不存在Spring MVC,同时需要在项目启动类上标识@EnableWebFlux注解
6. Spring WebFlux的 Mono 有什么用处?
使用 Mono 可以帮助构建出更高效、更具响应性的异步应用程序,同时也能够更好地管理资源并处理异步操作中的各种情况
它在处理单个值的异步场景以及构建复杂的异步处理流程时非常有用,同时能够使用Mono来进行一系列的链式操作
简单的说,可以把它想象成是一个代码方法执行的组装器,以提供初始化数据,随后由订阅者按照设定的每一步按照顺序进行执行,同时这个执行的过程是异步的,不会占用主线程的执行时间,主线程也可以在Mono订阅者执行结束后捕获其执行结果

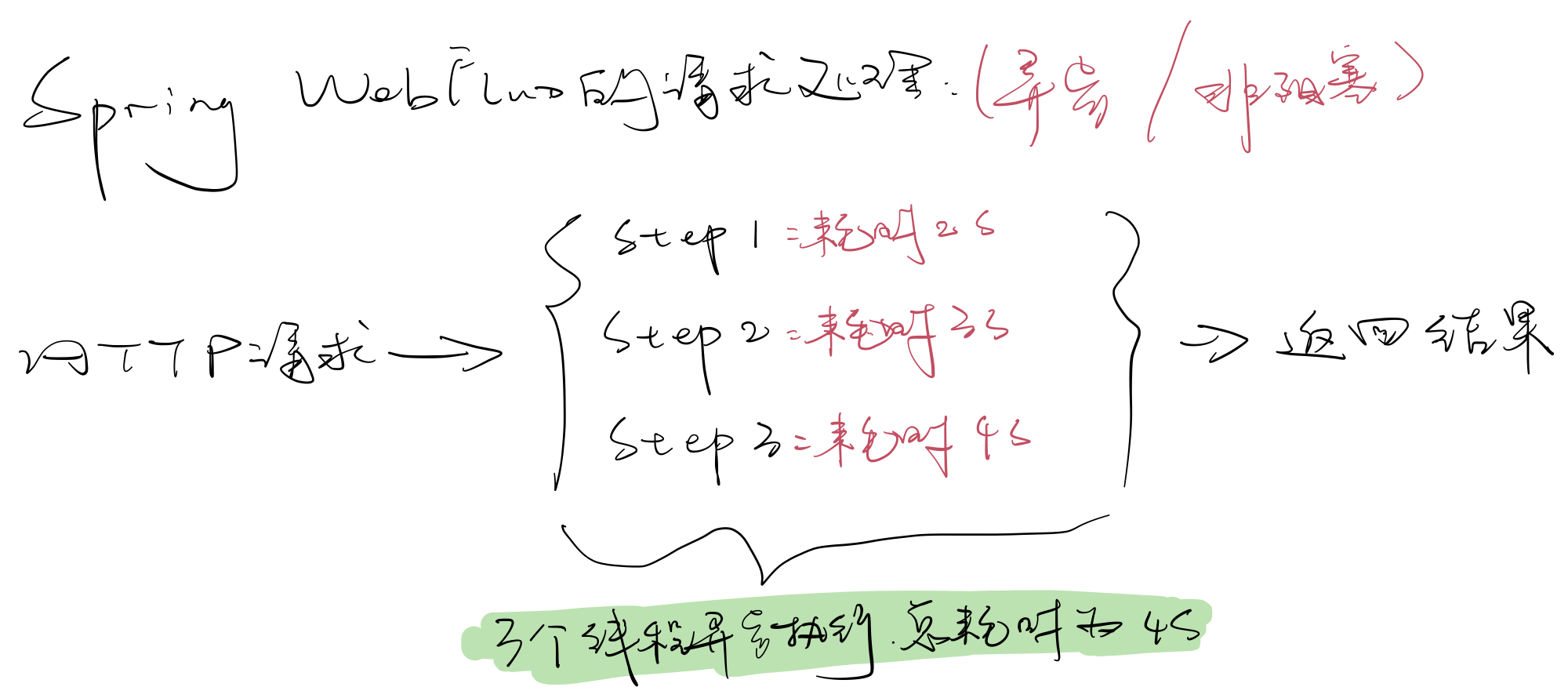
假设存在业务场景,需要执行步骤A,步骤B和步骤C,每个步骤的执行耗时均为1秒钟,则可使用Mono做以下异步处理:
1 | public class Solution { |
执行结果为以下:
1 | 18:29:58.132 [parallel-3] INFO - Step C completed |
可以看到通过Mono能够使得三个互不相干的耗时步骤并行异步执行,从而达到节省时间的作用,实际上Mono只是一个执行事件的发布器,而真正执行对应事件内容的是订阅者这个角色
7. Spring WebFlux中的Flux有什么作用?
Flux也是一个类似于Mono的事件发送器,唯一不同的点在于Flux的初始化数据可以是0个或多个,而Mono的初始化数据则只有0个或1个,Flux发送的多个事件实际上是顺序执行的,也就是说,订阅者在接收到Flux的初始化数据项后,会按照数据项的顺序进行执行
同时在默认情况下,如果在顺序处理的过程中出现了异常,则会中断所有的执行动作,后续未处理的数据将不再处理,当然也可以通过自定义的onErrorResume和onErrorReturn来处理过程中具体的异常,从而达到出现异常依然能够继续执行的效果

简单的理解,Flux和Mono的区别就是初始数据数量上的差异
假设存在5个初始数字,期望按顺序打印对应数值,并在打印完成后,对齐转化为字符串形式,执行过滤操作,随后再次打印,整个过程用Flux并行操作为以下:
1 | import reactor.core.publisher.Flux; |
执行结果为以下:
1 | 19:34:53.107 [parallel-1] INFO - [Step 1] Executed on Thread ID: 12 |
可以看到本质上过程与Mono并无差异,差异较大的是初始数据的限制
8. 为什么要叫Mono?
Mono 这个词来自希腊语,意为 “单一”、”独一无二”。在响应式编程中,Mono 是一种数据流类型,表示一个包含零个或一个数据项的流。它强调了在该数据流中只有一个值的特点,与 “单一” 或 “独一无二” 的概念相符合
在 Reactor 框架中,Mono 类型代表了一个包装了单一数据值的异步计算或操作。它可以包含一个数据项,也可以表示一个空的数据流(没有数据项),并可以在未来的某个时间点产生结果
因此,Mono 这个命名在一定程度上传达了该类型的特性和用途,即表示单一的、独特的数据流。这是响应式编程中的一种通用术语,用于区分不同类型的数据流,如 Mono 和 Flux(表示多个数据项的流)
9. 为什么要叫Flux?
在响应式编程中,Flux 是另一种数据流类型,表示一个包含多个数据项的流。这个名字传达了一个流可以包含多个不同数据项的概念
Flux这词的灵感来自于物理学中的 “流量”(flow),表示物质或能量在空间和时间中的传递。在响应式编程中,数据流的概念类似于物质或信息在程序中的传递
同时,Flux 也可以在某种程度上暗示流的持续性和变化性。就像物质的流量可以随时间变化一样,Flux 数据流中的数据项也可以随时间发生变化
Flux 这个命名体现了该数据流类型的特性,即表示多个数据项的流,与物质或信息的传递、流动概念相符合。这种命名方式有助于更好地理解 Flux 在响应式编程中的用途和特点
10. Mono.zip有什么作用?
Mono.zip 是 Reactor 库中的一个操作符,用于将多个 Mono 对象的结果合并成一个元组,具体来说,它会等待所有的 Mono 都完成,并将它们的结果合并成一个包含每个 Mono 结果的元组
如下所示:
1 | Mono<String> mono1 = Mono.just("Hello"); |
Mono.zip可以等待mono1, mono2, mono3都执行完成后,再开始触发事件,会将各个Mono的结果合并为元组,可以通过元组的 getT1()、getT2() 和 getT3() 方法获取每个 Mono 的结果
Mono.zip 操作符会等待所有的 Mono 都完成后才会触发订阅,因此它适用于需要同时等待多个异步操作完成的场景
11. Tuple是什么意思?
Tuple(元组)是计算机编程中的一个概念,用于表示一个有序、固定数量的元素集合,元组允许在一个数据结构中存储多个不同类型的值,这些值可以按照一定的顺序访问
1 | Mono.zip( |
Flux.zip 操作符的作用是将多个 Mono / Flux 对象的结果组合成一个元组,元组中的每个元素对应一个 Mono / Flux 的结果,如果涵盖多个结果,可以使用 tuple.getT1()、tuple.getT2()、tuple.getT3() 来访问元组中的每个元素,获取从不同数据源获取的数据
元组的概念在不同的编程语言中可能有不同的实现方式和用法,但基本思想都是类似的:将多个值按照顺序组合在一起,方便操作和处理
12. onErrorResume和onErrorReturn的区别?
onErrorResume 和 onErrorReturn 都是 Reactor 框架中用于处理错误的操作符,它们之间的主要区别在于它们处理错误时的行为不同
onErrorResume
onErrorResume用于在出现错误时提供一个备用的数据流,以继续执行后续操作可以返回另一个
Flux或Mono对象,或者返回一个函数生成的数据流这个备用数据流可以是一个包含默认值的数据流,也可以是一个根据错误类型进行不同操作的数据流
onErrorResume允许你根据错误类型来选择不同的处理逻辑,可以更加灵活地处理错误情况
1 | Flux<Integer> numbers = Flux.just(1, 2, -3, 4, 5); |
- onErrorReturn
onErrorReturn用于在出现错误时返回一个默认值,然后终止数据流,不再执行后续操作- 只能返回一个值,不能返回另一个数据流
onErrorReturn不允许根据错误类型来选择不同的处理逻辑,它的行为是固定的,只能返回一个预先设定的默认值
1 | Flux<Integer> numbers = Flux.just(1, 2, -3, 4, 5); |
13. map和flatMap有啥区别?
map 操作符
map操作符用于对数据流中的每个数据项进行映射,返回一个新的数据项,可以使用map来对每个数据项执行一个操作,将其转换为另一种类型或进行其他变换map操作符会对数据项进行一对一的映射,不会改变数据项的个数输入一个数据项,输出一个数据项,简单的理解就是n个数据项经过map转换过后还是n个数据项
1 | Flux<Integer> numbers = Flux.just(1, 2, 3); |
- flatMap 操作符
flatMap操作符用于对数据流中的每个数据项进行映射,并将映射结果合并成一个新的数据流- 适用于在映射操作中生成多个数据项或另一个数据流
flatMap操作符可以用于数据项的变换、数据流的拆分、合并等操作,它会改变数据项的个数,简单的理解就是n个数据经过flatMap转换过后可能会是多个数据线
1 | Flux<Integer> numbers = Flux.just(1, 2, 3); |
14. Mono.subscribeOn有什么用处?
Mono.subscribeOn 方法用于指定订阅操作在哪个调度器上执行,在响应式编程中,调度器(Scheduler)用于控制操作在不同线程或线程池中执行,从而实现并发和并行处理
默认情况下,如果没有使用Mono.subscribeOn(Schedulers.parallel)方法指定调度器,则Mono事件的订阅者默认会在主线程中执行,实际事件会以同步的方式进行
简单来说,Mono.subscribeOn 方法允许在订阅时指定一个调度器,以便在订阅操作执行时,将整个订阅链上的操作切换到指定的线程池中执行,这可以在一些情况下优化异步操作的执行环境,如避免在主线程上执行耗时操作,从而防止主线程阻塞
如以下例子:
1 | Mono.just("Hello, world!") |
执行结果为:
1 | 11:47:48.494 [main] INFO - Mapping on thread: main |
从执行结果可以看出,默认情况下,Mono所发布的事件都将在主线程中执行 ,因此个人觉着,如果,在对Mono抛开使用并行调度器,失去了其最大的特性:异步Spring WebFlux深度调研后发现,其所说的异步特性,实际上与我们普通认知异步线程有蛮大的差别,同样一行代码,写在了一个方法中,在命令式编程模型中,代码行过后便是意味着该行代码已经执行,但在响应式编程模型中,代码行扫过之后并不意味着已经执行,而是意味着该事件已随时准备好,等待订阅者进行订阅消费
因此所谓的异步实际上指的是代码不实时运行的异步,同时非阻塞指的也是这个意思,当使用Mono / Flux将耗时操作包裹起来,实际上该代码并不会立即执行,而是会继而等待订阅者订阅事件,因此实际上如果对应的代码是会阻塞的,也会由于Mono / Flux的特性令其成为非阻塞状态,从而等待发布事件
15. Schdulers调度器有多少种类型?
Schedulers.immediate(): 该调度器会立即在当前线程上执行操作,这是默认的调度器
Schedulers.single(): 该调度器使用单个线程来执行操作,适用于需要顺序执行、维护状态或避免并发的场景
Schedulers.parallel(): 该调度器使用固定数量的线程来执行操作,通常适用于 CPU 密集型的并发操作。可以通过参数设置线程数
Schedulers.boundedElastic(): 该调度器使用弹性线程池,在需要时动态创建新线程,适用于 I/O 密集型的并发操作,但会限制最大并发线程数,适用于 I/O 密集型操作,避免过多的线程竞争
Schedulers.fromExecutorService(ExecutorService): 可以使用自定义的
ExecutorService来创建调度器,适用于需要更精细控制的场景
CPU 密集型操作适合使用 Schedulers.parallel(),I/O 密集型操作适合使用 Schedulers.boundedElastic(),Schedulers.single() 可用于需要串行执行的场景,Schedulers.immediate() 用于测试或需要在当前线程上执行的情况
16. 冷流和热流是什么?
冷流:当多次订阅同一次Mono / Flux时,数据流将重新执行,称之为冷流
热流:在重复订阅同一个相同的事件时,数据流的处理结果将被复用,默认情况下使用的是冷流
如下方代码,默认采用的是冷流:
1 | Flux<Integer> numbers = Flux |
上面的例子中,1到4被发布两次,一次针对第一个订阅者,一次针对第二个订阅者
如果希望数据处理结果缓存起来,可以使用热流
在Project Reactor中,可以使用share() / cache()方法
1 | var numbers = Mono.just(1) |
通过cache()方法,numbers事件最终只会发布1次
17. WebFlux为什么不建议使用JDBC?
根据各项压力测试结果,结果表明在WebFlux使用JDBC的情况下,整个吞吐量远不如Spring MVC + JDBC的配置,如下所示:
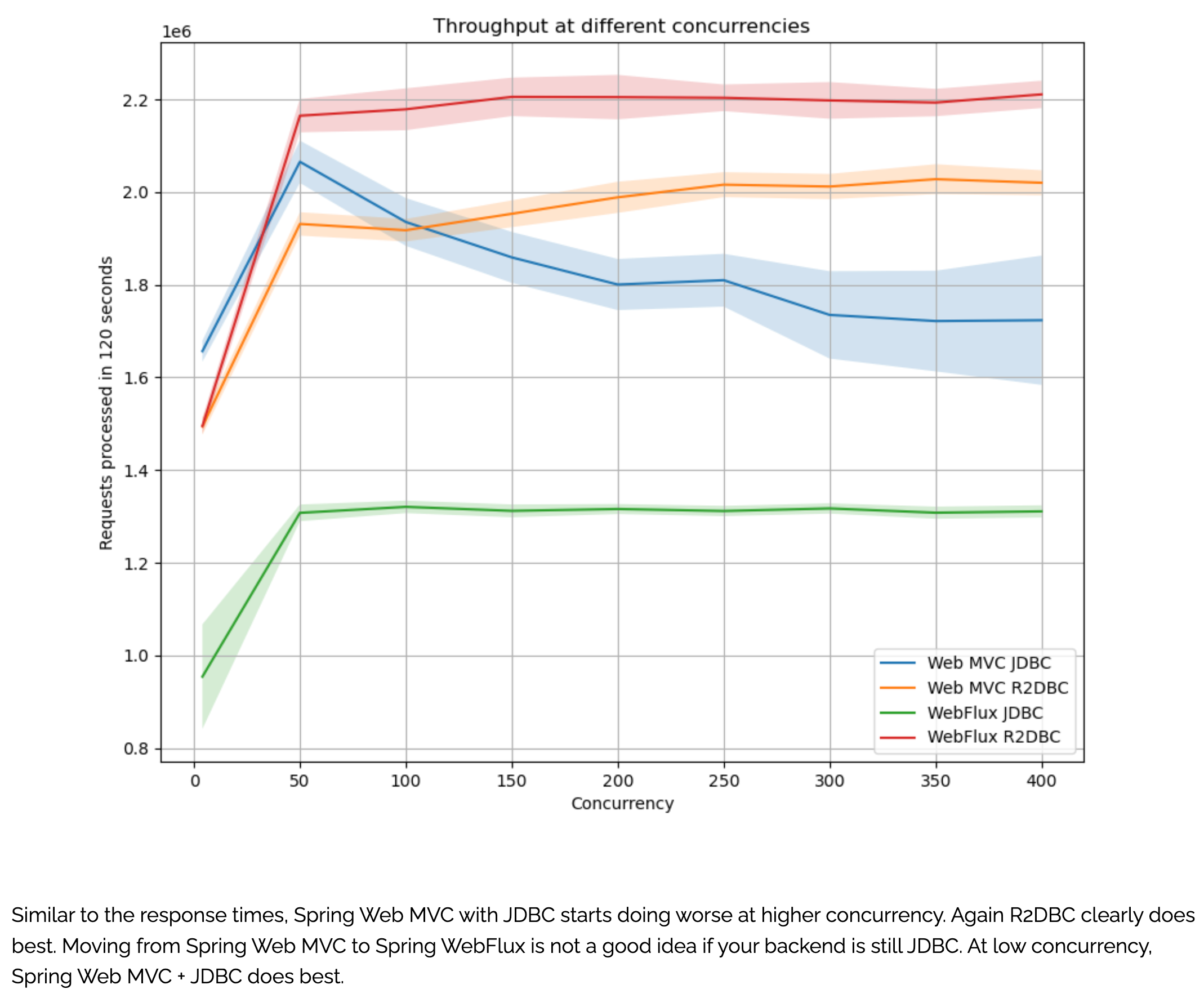
因此在使用WebFlux的情况下,建议使用的是R2DBC
18. 什么是R2DBC?
R2DBC(Reactive Relational Database Connectivity)是一种响应式的关系型数据库连接规范和库,用于在异步、非阻塞的环境中与关系型数据库进行交互。R2DBC 的目标是允许开发者在响应式应用程序中使用关系型数据库,以实现高性能、高并发、低延迟的数据访问
R2DBC 与传统的 JDBC(Java Database Connectivity)不同,它采用了响应式编程模型,支持异步操作,可以更好地适应高并发的情况,而不会阻塞应用程序的线程,这对于需要处理大量并发请求的应用程序(如 Web 服务)特别有用
简单地理解就是R2DBC支持以Mono的异步非阻塞方式来访问数据库
其实质为一层规范,底层实现是由各个不同的数据库类型组成,对外提供为统一的操作接口
19. Mono & Flux常用API
- doNext / doOnNext:在每个数据项产生时执行操作,用于观察或记录数据流的处理过程
1 | Flux.range(1, 5) |
- subscribe:注册一个订阅者以处理数据流中的事件,包括
onNext、onError和onComplete
1 | Flux.range(1, 5) |
- subscribeOn / publishOn:指定操作的执行调度器,用于在不同的线程上执行操作
1 | Flux.range(1, 5) |
- map:对数据流中的每个数据项执行映射操作,将数据项转换为另一种类型
1 | Flux.range(1, 5) |
- flatMap:对数据流中的每个数据项执行异步操作,并将结果扁平化成一个新的数据流
1 | Flux.range(1, 5) |
- zip:将多个
Mono或Flux的结果合并成一个元组,等待所有操作完成后进行处理
1 | Mono.zip( |
- block:等待操作完成并返回结果,但需要注意可能引发阻塞,适用于特定情况下
1 | Flux.range(1, 5) |
- onErrorResume / onErrorReturn:处理操作中的错误情况,提供备用值或执行替代操作
1 | Flux.range(1, 5) |
- defer:用于将初始化数据操作放置到发布事件时再执行,防止在初始化数据时耗费大量时间
1 | var deferMono = Mono.defer(() -> { |
n. 参考链接
- Spring WebFlux
- Spring Boot WebFlux
- 深入剖析 Spring WebFlux
- ProjectReactor Backpressure
- 响应式编程中Mono和Flux的区别
- Spring 5 WebFlux Mono and Flux
- Async requests in webflux are not async
- How to turn a Mono into a truly asynchronous (not reactive!) method call?
- Spring: Blocking vs non-blocking: R2DBC vs JDBC and WebFlux vs Web MVC
m. 图集